

Uwaga, uwaga! Pierwszy wpis nowej dziesięciolatki i jednocześnie już trzeci o Pythonie i inwestowaniu. Co prawda ostatnio rozmawiałem z koleżanką z korpo, która twierdziła, że 2020 to wciąż poprzednie dziesięciolecie. Argument jest taki, że zaczynamy liczyć od roku numer 1. Ale co w takiej sytuacji z rokiem zerowym? Hę? Mi się podoba koncepcja, że wkroczyliśmy w lata 20-te i tego będę się trzymał.
Jak nazwa wpisu wskazuje (lub nie), dzisiaj będzie o obligacjach korporacyjnych. Wskazuje, jeżeli wiesz, że wspominane papiery są notowane na rynku warszawskiej giełdy o nazwie Catalyst. Nie wskazuje, jeżeli dałeś się nabrać na obrazek przedstawiający część układu wydechowego samochodu zwanego katalizatorem (trochę stylizowany, ale jednak).
Zastanawiałem się chwilę nad słowem, które zainspirowało tytuł i olśnił mnie pewien dualizm pomysłu na ten wpis. Kod w Pythonie, którym się tu z Wami podzielę, pełni przecież zarówno funkcję katalizatora w rozumieniu motoryzacyjnym – czyli w zasadzie filtra, jak i czegoś, co (gdyby chodziło o chemię) umożliwia proces. Niebawem wszystko się wyjaśni…
Od początku – co to w ogóle są obligacje korporacyjne. Generalnie można powiedzieć, że kupując obligacje korporacyjne, zamiast trzymać pieniądze w skarpecie, pożyczasz je firmie-emitentowi w zamian za obiecany procent. Oczywiście przy okazji dom maklerski i skarbówka upominają się o swój haracz. I jeszcze jedno – jak masz pecha, to hajsu nie odzyskasz, bo firma nie da rady obligacji wykupić (to jest fachowo nazywane ryzykiem inwestycyjnym). To co? Piniendze do skarpety? Mam nadzieję, że nie. Gwoli ścisłości: na rynku Catalyst notowane są również obligacje spółdzielcze, komunalne i skarbowe, a także listy zastawne.
Wyobraź sobie, że idziesz do sklepu po pastę do zębów bez wcześniejszego przygotowania. Nie wiesz nic o tym co daje mycie zębów jedną, a co drugą. Która pozwoli ci zrezygnować z odświeżaczy powietrza w mieszkaniu, a która usunie kamień z zębów z siłą wodospadu. Ciężko będzie zdecydować, prawda? Ewidentnie przydałby się, jak to mówią po korpoludzku, risercz.
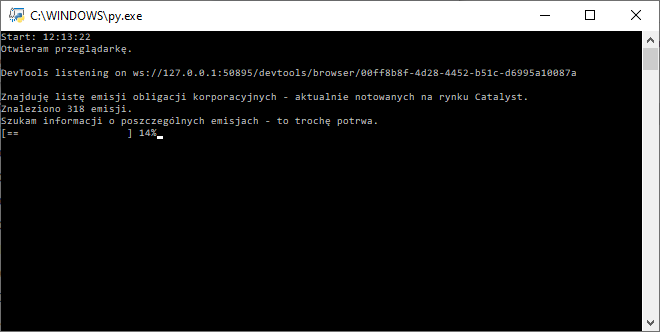
Aby oszczędzić czas, pieniądze oraz zminimalizować ryzyko niezadowolenia z kupionej pasty, poleca się zebrać informacje o dostępnych opcjach. Wierzcie lub nie, z inwestowaniem w obligacje korporacyjne jest podobnie. Tak, tak! A skąd wziąć informacje? Można szukać w gazetach, zadzwonić do kolegi „co się zna” lub zwyczajnie wygooglać. Próba zebrania informacji ręcznie jest karkołomnym pomysłem – a to z powodu ilości dostępnych opcji. Na dzień pisania tego zdania, na rynku Catalyst notowanych było 318 emisji. Szacunek, jeżeli by się komuś chciało robić to ręcznie. A raczej nie, bo to chyba lekko głupie 😉
Jak się pewnie domyślacie, w tym momencie wpełza Python i mówi – zrobię to za Ciebie. A co dokładnie? Otóż przede wszystkim:
- otworzy sobie przeglądarkę internetową
- odwiedzi stronę www rynku Catalyst
- przejrzy stronę i pobierze listę kodów aktualnie notowanych obligacji korporacyjnych
Wszystko śmiga, wiemy już jakie obligacje są notowane i można je kupić na rynku wtórnym (w sensie od kogoś, kto już je posiada). Kolejnym krokiem jest próba dowiedzenia się czegoś więcej. Na przykład jak często wypłacane są odsetki, jakie jest aktualne oprocentowanie, ile zostało okresów odsetkowych do daty wykupu. Jak pozostać takie informacje? Wystarczy skorzystać z serwisu obligacje.pl będącego własnością prywatnej spółki z o.o. zarejestrowanej w Warszawie (brak powiązań z autorem). Każda aktualna emisja obligacji ma w tym serwisie dedykowaną podstronę. Adres do tej strony ma zawsze taką samą konstrukcję:
https://obligacje.pl/pl/obligacja/ + kod obligacji
I tu znów, sycząc z radości, Python zrobi robotę za nas.
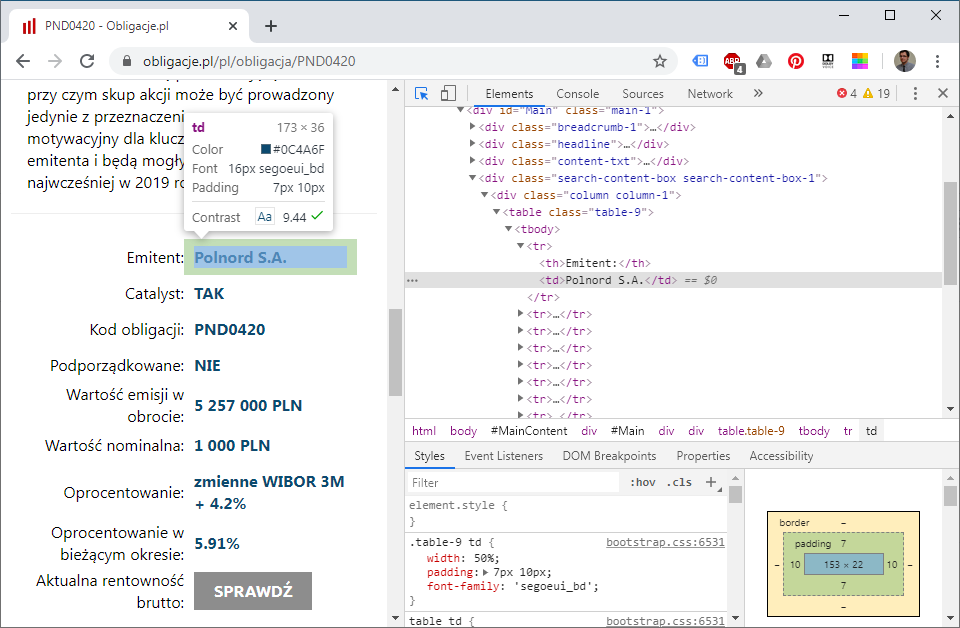
Pewnie wiecie, albo nie, że w każdej przeglądarce internetowej jest opcja podglądu kodu przeglądanej strony. Zerknięcie w ten kod jest kluczem do zrozumienia jak zaprogramować Pythona do szukania informacji. Interesujące nas strzępki kodu strony będą zawsze poprzedzone lub będą poprzedzać jakieś regularnie występujące zbitki znaków. Na przykład nazwa emitenta poprzedzona jest ciągiem:
<th>Emitent:</th>\n<td>
gdzie \n oznacza przejście do nowej linii. Ten ciąg znaków to tak zwane wyrażenie regularne – coś, o czym jak się dowiedziałem, to z wrażenia wybuchł mi mózg.
Pierwszy raz o wyrażeniach regularnych (aka regexach) dowiedziałem się z książki „Automate the Boring Stuff with Python”, który serdecznie polecam. Autor całą jej treść zamieścił na swojej stronie internetowej (o tu). Czacha dymi, uwierzcie mi na słowo 🙂
Prosimy ładnie Pythona, żeby przejrzał kod strony serwisu obligacje.pl w poszukiwaniu konkretnego ciągu znaków i zwrócił zadaną jego część. Kontynuując przykład nazwy emitenta, całe wyrażenie regularne wygląda tak:
(<th>Emitent:</th>\n<td>)(.*)(<)
nawiasy oddzielają 3 poszukiwane części:
- <th>Emitent:</th>\n<td>, gdzie jak już wspomniałem \n oznacza nową linię
- kropkę i gwiazdkę, czyli dowolny ciąg znaków
- znak „<”
Jesteśmy zainteresowani tylko punktem 2 i to tę część ma dla nas zapamiętać Python. To jest właśnie poszukiwana nazwę emitenta.
Genialne? Dla mnie odjazd! Zapewne część z Was powiedziałaby „Sztos”.
Podobnie ustalamy sposób poszukiwania pozostałych interesujących nas informacji. A elementów tych łącznie jest 13, chociaż nie wszystkie pochodzą bezpośrednio ze strony WWW:
- nazwa emitenta
- kod obligacji
- wartość nominalna
- waluta
- typ oprocentowania
- baza oprocentowania
- oprocentowanie w bieżącym okresie
- liczba okresów odsetkowych
- częstotliwość wypłat
- liczba pozostałych okresów odsetkowych
- następna data wypłaty odsetek
- następna data ustalenia praw do odsetek
- data wykupu
Elementami wyliczanymi będą po pierwsze obie „liczby okresów” (8 i 10), które uzyskiwane są poprzez sprawdzenie długości list dat pobranych z www. Dodatkowo chodzi o „następne daty” (11 i 12), gdzie Python ma zwrócić najbliższą datę do bieżącej z listy dat pobranych z kodu źródłowego strony.
Magia? Tylko na pierwszy rzut oka. Mimo, że to trzeci wpis o Pythonie na moim blogu, to kod ten ma już swoje lata i znacznie ewoluował. Był to pierwszy automat w Pythonie jaki kiedykolwiek napisałem na własne potrzeby (wieczorami na wakacjach w Karwi tak na marginesie). Dokładałem funkcjonalności krok po kroku, zastanawiając się co się przyda i jak to uzyskać. Zacząłem z myślą o jednej spójnej tabelce, gdzie informacje o wszystkich emisjach mam pod ręką i mogę szybko przejrzeć. Wiedziałem co chce osiągnąć, więc czemu miałoby się to nie udać?
Ostateczny kod (który oczywiście znajdziecie na Githubie) ma jeszcze kilka bajerów, jak na przykład pasek statusu, gdy zbierane są informacje. Of kors na koniec wszystko ląduje w bazie MSSQL.

GPW (this link opens in a new window) by Ukasz123D (this link opens in a new window)
Experimenting with Python for the sake of gathering and analysing Warsaw Stock Exchange data
Kod działa mniej więcej 2 minuty. W tym czasie buduje dla mnie tabelkę z informacjami o wszystkich notowanych aktualnie obligacjach korporacyjnych. Tyle mogę poświęcić na zbieranie danych, bo na więcej mnie nie stać. Przed rzuceniem się w wir zakupów pozostaje jeszcze analiza – o sposobach na to jak sobie w tym pomóc w kolejnym odcinku, który ukaże się, gdy się ukaże 🙂
Kończę klamrą: dlaczego katalizator? Ponieważ bez informacji o tym co mogę kupić na rynku Catalyst pewnie nie kupił bym nic. Kod umożliwia mi więc inwestowanie, a przy okazji wyłuskiwania dla mnie interesujących informacji oszczędza czas, którego w domu 3+1 (Żona i dwie córki oraz ja) za dużo nie ma.
Idźcie i uczcie się (jeżeli macie ochotę, bo jak nie, to nie). Pa!
Jedna odpowiedź do “Catalysator”